2.3. 数据分析例子¶
现在就开始文章开始说的数据分析例子,即从一份公司财富数据中分析公司的利润变化情况。
2.3.1. 命名 notebooks¶
首先,给 notebook 命名一个有意义的名字,比如 jupyter-notebook-tuorial,
可以直接在 notebook 界面直接点击上方文件名,如果未命名,那就是 Untitle.ipynb ,
当然也可以返回管理界面进行命名,如下所示,选择 notebook 后,上方会出现一行选项,包括:
Duplicate:复制
Shutdown:停止该 notebook 的 kernel
View:查看 notebook 内容
Edit :编辑其 metadata 内容
以及还有一个删除文件的选项。如 图 2.18 所示。
图 2.18 选项界面¶
注意,关闭 notebook 的界面并不会关掉 notebook 的 kernel,它会一直在后台运行, 在管理界面看到 notebook 还是绿色状态,就表明其在运行,这需要选择 Shutdown 选项, 或者命令行里关掉 Jupyter notebook 的命令。
2.3.2. 准备工作¶
首先导入一些需要用的第三方库:
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="darkgrid")
pandas 用于处理数据,Matplotlib 用于绘制图表,而 seaborn 可以让图表更加漂亮。 通常也需要导入 Numpy ,不过在本例中我们将通过 pandas 来使用。此外, %matplotlib inline 这并不是 python 的命令,它是 Jupyter 中独有的魔法命令, 它主要是让 Jupyter 可以捕获 Matplotlib 的图片,并在单元输出中渲染。
接着就是读取数据:
df = pd.read_csv('fortune500.csv')
2.3.3. 保存和检查点(checkpoint)¶
在开始前,要记得定时保存文件,这可以直接采用快捷键 Ctrl + S 保存文件, 它是通过一个命令--“保存和检查点”实现的,那么什么是检查点呢?
每次创建一个新的 notebook,同时也创建了一个 checkpoint 文件,
它保存在一个隐藏的子文件夹 .ipynb_checkpoints 中,并且也是一个 .ipynb 文件。
默认 Jupyter 会每隔 120 秒自动保存 notebook 的内容到 checkpoint 文件中,
而当你手动保存的时候,也会更新 notebook 和 checkpoint 文件。
这个文件可以在因为意外原因关闭 notebook 后恢复你未保存的内容,
可以在菜单中 File->Revert to Checkpoint 中恢复。
2.3.4. 对数据集的探索¶
现在开始处理我们的数据集,通过 pandas 读取后得到的是称为 DataFrame 的数据结构, 首先就是先查看下数据集的内容,输入以下两行代码,分别表示输出数据的前五行,和最后五行的内容。
df.head()
df.tail()
如 图 2.19 所示:
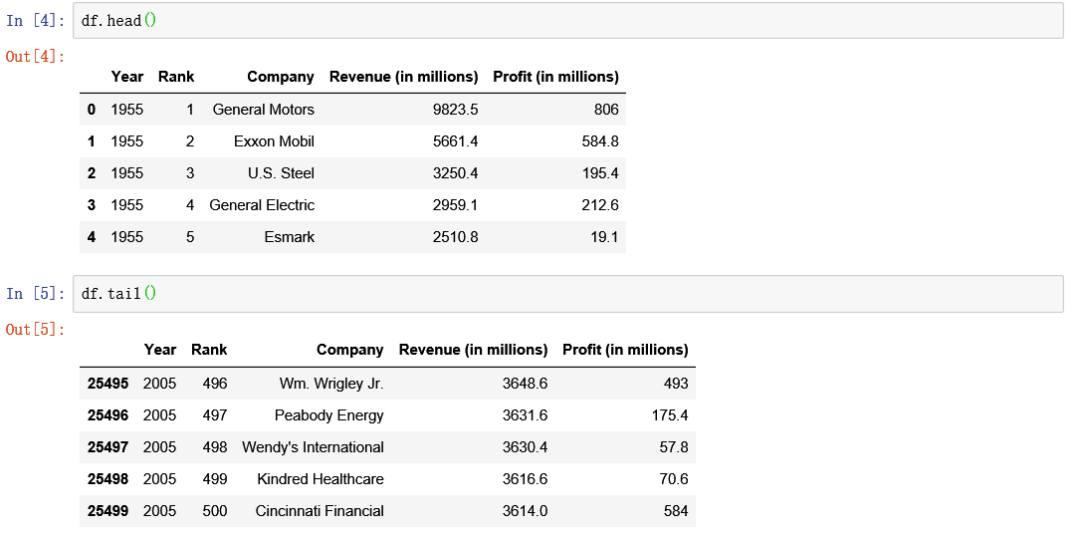
图 2.19 输出内容¶
通过查看,我们了解到每行就是一个公司在某一年的数据,然后总共有 5 列, 分别表示年份、排名、公司名字、收入和利润。
接着,为了方便,可以对列重命名:
df.columns = ['year', 'rank', 'company', 'revenue', 'profit']
然后,还可以查看数据量,如下所示:
len(df)
如 图 2.20 所示, 总共有 25500 条数据,刚好就是 500 家公司从 1955 到 2005 的数据量。

图 2.20 数据量¶
接着,我们再查看数据集是否和我们希望导入的一样, 一个简单的检查方法如 图 2.21 是否正确:
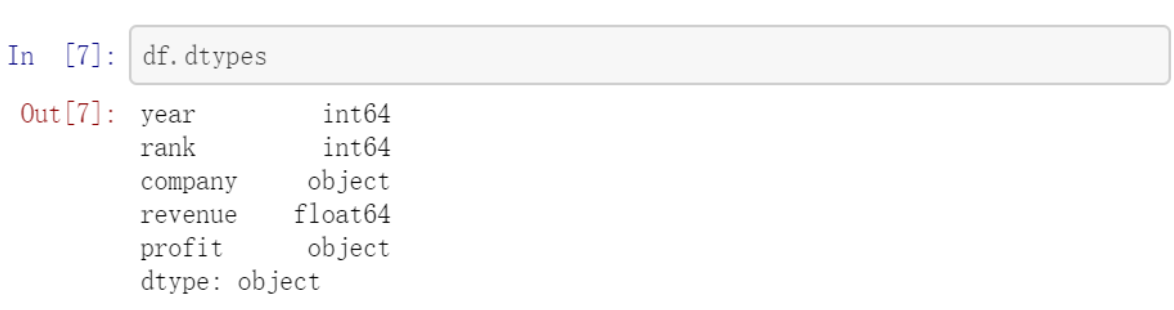
图 2.21 查看数据类型¶
这里可以发现 profit 数据类型居然是 object 而不是和收入 revenue 一样的float64 类型, 这表示其中可能包含一些非数字的数值,因此我们需要检查如 图 2.22 :
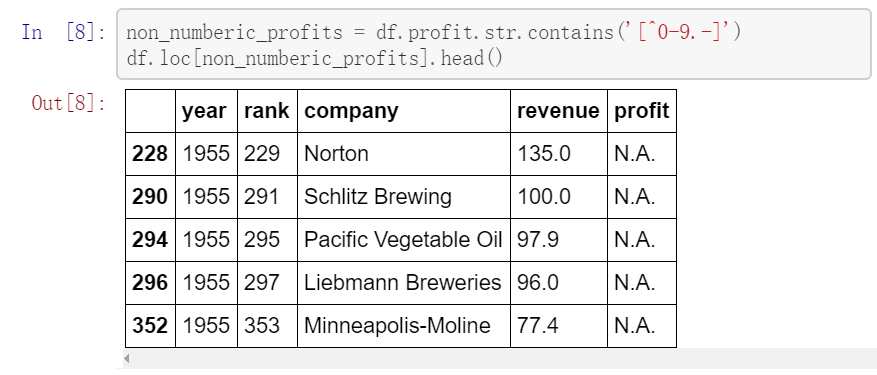
图 2.22 非数字的数值¶
输出结果表明确实存在非整数的数值,而是 N.A,然后我们需要确定是否包含如 图 2.23 :

图 2.23 其他类型的数值¶
输出结果表示只有 N.A ,那么该如何处理这种缺失情况呢,这首先取决有多少行数据缺失了 profit : 如 图 2.24 :

图 2.24 数据缺失情况¶
369 条数据缺失,相比于总共 25500 条数据,仅占据 1.5% 左右。 如果缺失的数据随着年份的变化符合正态分布,那么最简单的方法就是直接删除这部分数据集, 如 图 2.25 所示。
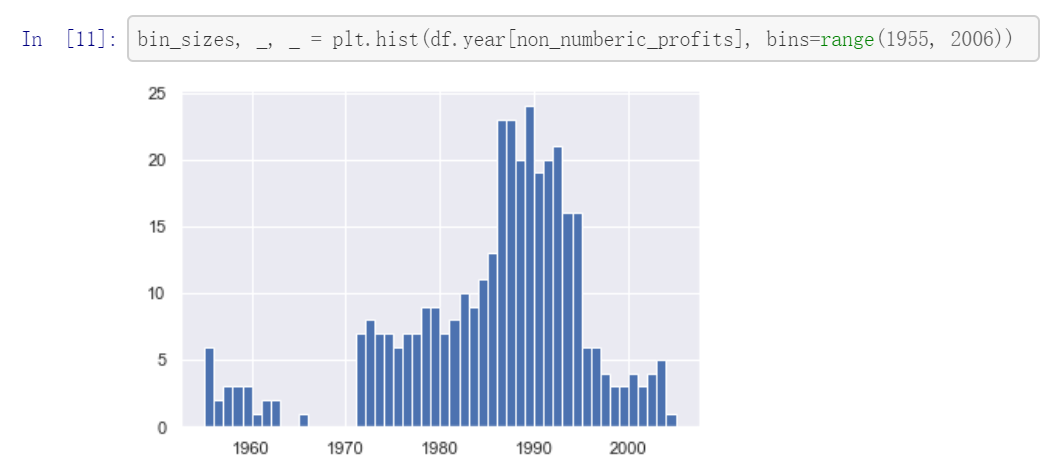
图 2.25 删除数据集代码¶
从结果看,缺失数据最多的一年也就是 25 条也不到,相比每年 500 条数据,最多占据 4%, 并且只有在 90 年代的数据缺失会超过 20 条,其余年份基本在 10 条以下, 因此可以接受如 图 2.26 所示。
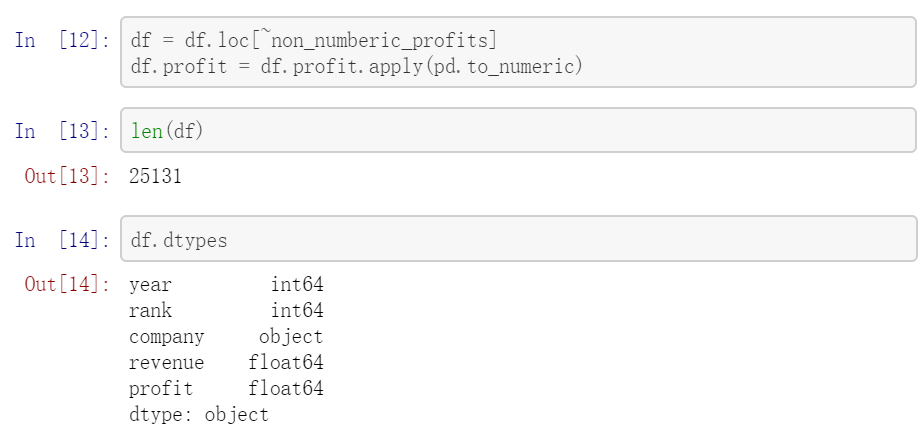
图 2.26 删除缺失值的数据代码¶
删除数据后,profit 就是 float64 类型了。
简单的数据探索完成了,接下来进行图表的绘制。
2.3.5. 采用 matplotlib 进行绘制图表¶
首先绘制随着年份变化的平均利润表,同时也会绘制如 图 2.27 。
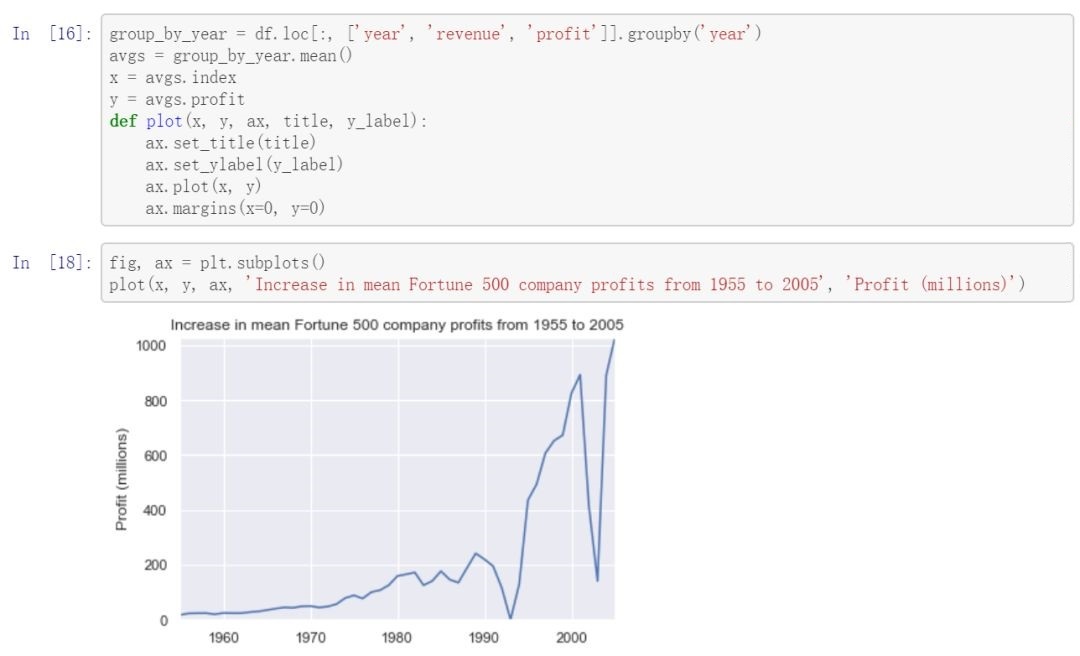
图 2.27 收入随年份的变化情况¶
结果看起来有点类似指数式增长,但出现两次巨大的下降情况,这其实和当时发生的事件有关系, 接下来可以看看如 图 2.28 :

图 2.28 收入的变化情况¶
从收入看,变化并没有像利润一样出现两次波动。
参考 https://stackoverflow.com/a/47582329/604687, 我们添加了利润和收入的标准差情况, 用于反馈同一年不同公司的差异情况, 如 图 2.29 :
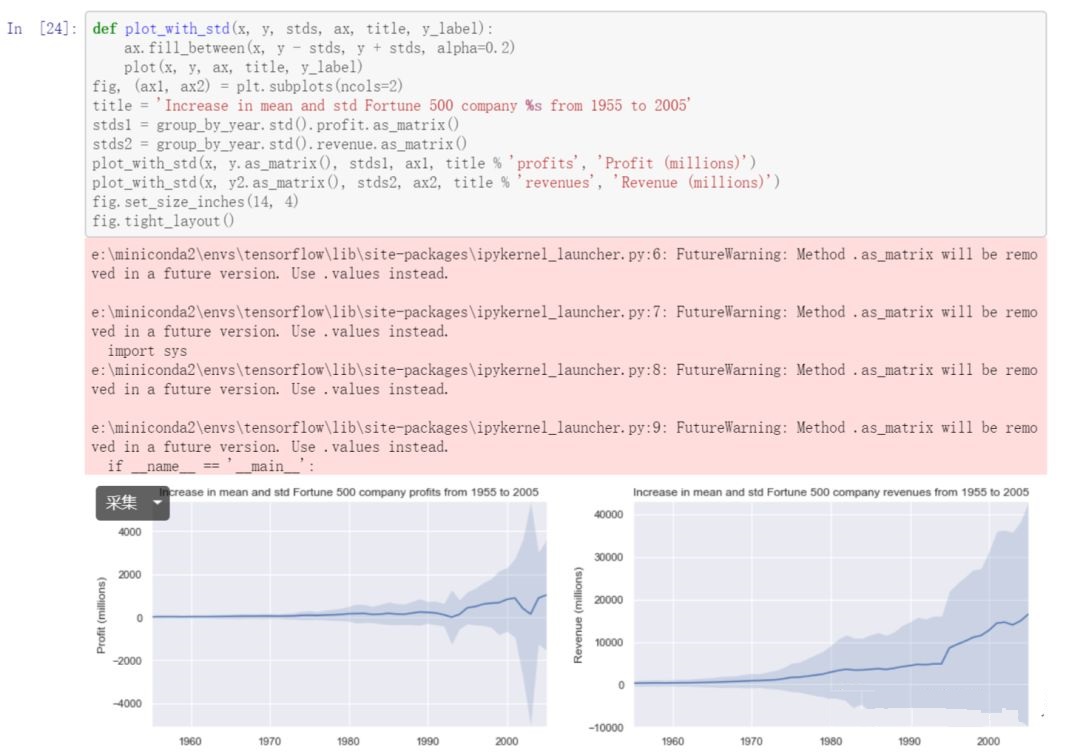
图 2.29 收入或者利润差距¶
结果表明了不同公司的差距还是很大的,存在有收入几十亿,也有亏损几十亿的公司。
其实还有很多问题可以深入探讨,但目前给出的例子已经足够入门 Jupyter notebook, 这部分例子展示了如何分析探索数据,绘制数据的图表。